Im April bieten wir keine Sprechstunde an, da der Termin auf die Osterferien fällt.
Die nächste OCR-Sprechstunde wird daher am 11. Mai stattfinden.
Im April bieten wir keine Sprechstunde an, da der Termin auf die Osterferien fällt.
Die nächste OCR-Sprechstunde wird daher am 11. Mai stattfinden.
Am Donnerstag, den 09.03.2023 um 15 Uhr findet die nächste offene OCR-Sprechstunde via Zoom statt. Bei dieser Gelegenheit können Sie wieder Fragen zum Thema automatische Texterkennung von Handschriften und Drucken stellen.
Sie können dem Meeting ohne vorherige Anmeldung unter folgendem Link beitreten: https://ocr-bw.bib.uni-mannheim.de/sprechstunde (Meeting-ID: 682 8185 1819, Kenncode: 443071).
Sollten Sie technische Probleme oder Fragen haben, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de).
Am Donnerstag, den 09.02.2023 um 15 Uhr findet die nächste offene OCR-Sprechstunde via Zoom statt. Bei dieser Gelegenheit können Sie wieder Fragen zum Thema automatische Texterkennung von Handschriften und Drucken stellen.
Sie können dem Meeting ohne vorherige Anmeldung unter folgendem Link beitreten: https://ocr-bw.bib.uni-mannheim.de/sprechstunde (Meeting-ID: 682 8185 1819, Kenncode: 443071).
Sollten Sie technische Probleme oder Fragen haben, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de).
Das Kompetenzzentrum OCR der UB Tübingen und der UB Mannheim veranstaltet in Kooperation mit dem Forschungsdatenzentrum in der Love Data Week (13. bis 17. Februar) einen Transcribathon auf der Texterkennungs- und Transkriptionsplattform eScriptorium. Die Teilnehmenden bekommen die Möglichkeit, die handschriftlichen Reisetagebücher des Tübinger Orientalisten Julius Euting (1839–1913) zu transkribieren.
Zum Auftakt des Transcribathons treffen wir uns am Montag, dem 13.02.2023, um 13.30 Uhr online via Zoom und besprechen die Funktionalitäten von eScriptorium sowie die Ziele des Transcribathons. Über die Woche können die Teilnehmenden dann fleißig transkribieren und in die spannenden Reiseberichte aus fernen Ländern wie Syrien, Ägypten und Algerien eintauchen. Am Freitag, dem 17.02.2023, um 13.30 Uhr treffen wir uns dann erneut, besprechen die Ergebnisse und küren die Sieger:innen des Transcribathons.
Anmeldung zum Auftakt: https://www2.bib.uni-mannheim.de/event-registration/index.php?eventkey=LDW-2023-02-13-online
Anmeldung zum Finale: https://www2.bib.uni-mannheim.de/event-registration/index.php?eventkey=LDW-2023-02-17-online
Sollten Sie am Auftakt nicht teilnehmen können, aber würden gerne am Transcribathon teilnehmen, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de)

Am Donnerstag, den 12.01.2023 um 15 Uhr findet die erste OCR-Sprechstunde des neuen Jahres via Zoom statt. Bei dieser Gelegenheit können Sie wieder Fragen zum Thema automatische Texterkennung von Handschriften und Drucken stellen.
Sie können dem Meeting ohne vorherige Anmeldung unter folgendem Link beitreten: https://ocr-bw.bib.uni-mannheim.de/sprechstunde (Meeting-ID: 682 8185 1819, Kenncode: 443071). Sollten Sie technische Probleme oder Fragen haben, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de).
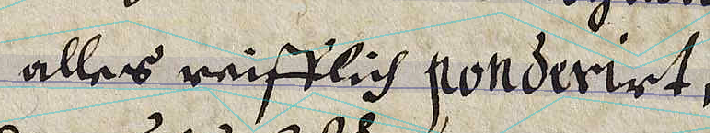
Der Frage nach dem bestmöglichen Ansatz beim Training von eigenen Modellen für die automatische Texterkennung von Handschriften ist die UB Tübingen nachgegangen. An verschiedenen Textkorpora vom mittelalterlichen Gebetbuch über Großbestände wie Juristische Konsilien bis hin zum Expeditionstagebuch des 20. Jahrhunderts wurden unterschiedliche Herangehensweisen getestet, wie sich mit dem geringstmöglichen Aufwand ein möglichst gutes Modell entwickeln lässt. Die Ergebnisse können im aktuellen o-bib-Heft Bd. 9 Nr. 4 (2022) nachgelesen werden.
Nachdem die erste offene OCR-Sprechstunde sich großer Beliebtheit erfreute, findet nun am Donnerstag, den 08.12.2022 um 15 Uhr die zweite Sprechstunde via Zoom statt. Bei dieser Gelegenheit können Sie alle Fragen zum Thema automatische Texterkennung und Transkriptionssoftware stellen.
Sie können dem Meeting ohne vorherige Anmeldung unter folgendem Link beitreten: https://ocr-bw.bib.uni-mannheim.de/sprechstunde (Meeting-ID: 682 8185 1819, Kenncode: 443071). Sollten Sie technische Probleme oder Fragen haben, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de).
Wir freuen uns wieder auf Ihr zahlreiches Erscheinen und sind gespannt auf die Themen, die dieses Mal auf uns warten!
Liebe OCR-Interessierte,
die Förderung für das Projekt OCR-BW durch das Ministerium für Wissenschaft, Forschung und Kunst ist Ende September ausgelaufen und somit ist das Projekt offiziell beendet. Das im Rahmen der Projektarbeit aufgebaute Kompetenzzentrum OCR wird jedoch weiterhin von der UB Mannheim und der UB Tübingen betrieben. Erfreulicherweise stehen Ihnen alle Beteiligten weiterhin beratend zur Verfügung und helfen Ihnen bei Fragen zur automatisierten Texterkennung von Drucken und Handschriften.
Ab Donnerstag, den 10. November, bieten wir von 15.00–16.00 Uhr (zunächst jeden 2. Donnerstag im Monat) eine offene OCR-Sprechstunde via Zoom als zusätzliches Serviceangebot an. In diesem niedrigschwelligen Angebot können Sie ohne vorherige Anmeldung alle Fragen rund um das Thema automatisierte Texterkennung loswerden. Sie können dem Meeting unter folgendem Link beitreten: https://tinyurl.com/ocr-sprechstunde (Meeting-ID: 682 8185 1819, Kenncode: 443071). Sollten Sie Probleme haben, wenden Sie sich an Larissa Will (larissa.will(at)uni-mannheim.de).
Nun schauen wir zurück auf eine ereignisreiche Projektlaufzeit mit vielen interessanten Anfragen und immer neuen Herausforderungen. Besonders freut uns, dass einige Kooperationen über das Projektende hinaus bestehen bleiben.
Wir bedanken uns für die Zusammenarbeit und hoffen, dass wir Sie vielleicht bald in unserer OCR-Sprechstunde begrüßen dürfen!
Ihr OCR-BW Team
Für all diejenigen, die momentan Transkribus nutzen, kann ein Vergleich mit der Open-Source-Alternative eScriptorium interessant sein. Transkribus gestattet zwar keine direkte Übertragung Ihrer darin trainierten Modelle, jedoch kann die Ground Truth, also die in Transkribus erstellte Transkription und die dazugehörigen Bilder, aus Transkribus exportiert und in eScriptorium importiert werden. Anschließend können Sie ein Modell in eScriptorium trainieren. eScriptorium ermöglicht Ihnen die einfache Weitergabe des trainierten Kraken-Modells. Sie finden die dazugehörige Anleitung auf der GitHub-Seite der UB Mannheim. Für Hinweise und Verbesserungsvorschläge sind wir immer dankbar.
Wenn Sie Fragen zu eScriptorium haben oder es selbst gerne ausprobieren möchten, dann wenden Sie sich an uns.
Ansprechpartnerin: Larissa Will, E-Mail: larissa.will(at)uni-mannheim.de
Passend zum Vortrag beim 3. OCR-BW-Workshop von Eric Veyel und Rainer Gräbeldinger (MARCHIVUM) über das Projekt „Mannheims historische Zeitungen online“ finden Sie in der 42. Ausgabe der Mannheimer Geschichtsblätter einen spannenden Artikel dazu.
Dr. Harald Stockert und Eric Veyel berichten hierbei über das Vorgehen von der Digitalisierung bis zur Online-Präsentation von insgesamt 300 Zeitungsbänden mit über 350.000 Einzelseiten. Das MARCHIVUM war schon vor der Pandemie Vorreiter in Sachen Digitalisierung, und von einer kleinen Ein-Personen-Scanstation im Haus entwickelte sich die Abteilung zu einem Digitalisierungszentrum mit hoher Expertise und entsprechender Ausstattung. Das MARCHIVUM leistet so einen wichtigen Beitrag zur Erforschung und Aufarbeitung der Mannheimer Stadtgeschichte. Auch weiterhin sollen nach und nach historische Druckerzeugnisse auf dem Portal veröffentlicht werden, wie beispielsweise Theaterzettel des Mannheimer Nationaltheaters, aber auch weitere Zeitungen.
Das Projektteam von OCR-BW freut sich, durch die die bisherige sowie zukünftige Beratung sowie die Bereitstellung von Frakturmodellen Teil dieses erfolgreichen Projekts zu sein!